Clustering in Machine Learning
Clustering is an unsupervised learning technique used in machine learning to uncover potential relationships and groupings, commonly known as "clusters".
What is a cluster? It's a collection or group of objects that share some, but not all, characteristics. They're similar but not identical. The concept of a cluster is consistent across fields like machine learning, statistics, and marketing.
In machine learning, clustering is also referred to as unsupervised classification.
A Practical Example
In this dataset, there are three features: x1, x2, x3.
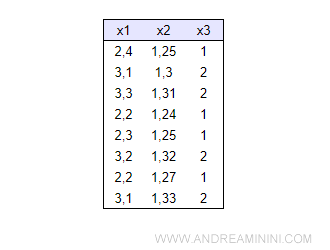
The machine lacks label information and any learning function. There's no supervision.
Despite this, the table reveals a significant relationship between x1, x2, and x3.
To illustrate this, let's temporarily ignore x3 and plot x1 and x2 on a Cartesian graph.
Even in this two-dimensional graph, a pattern and regularity in the data begin to emerge.
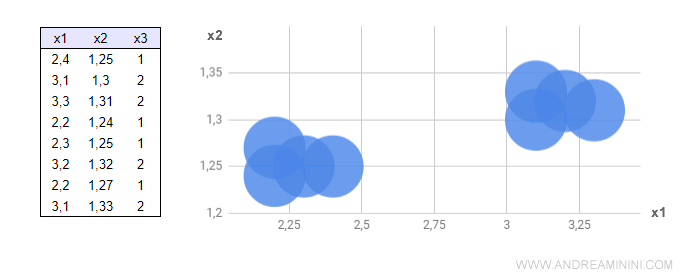
Next, I assign different colors (blue, red) to the coordinates (x1, x2) to represent the third feature, x3, or the third dimension.
Blue for x3=1 and red for x3=2.
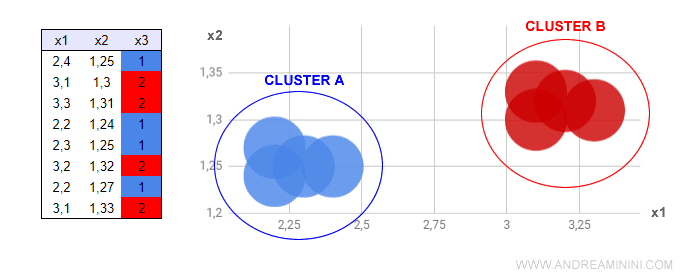
Now, the clustering is immediately apparent even to the naked eye.
In clusters A and B, similar data points are grouped together.
This way, the machine learns significant information from the data, without any guidance from a supervisor.
Note. This is a simple two-dimensional example, but it illustrates the concept. In reality, clustering is particularly useful when applied to multidimensional databases, where the human eye can't discern patterns.
In machine learning, clustering algorithms are used to identify relationships between data through a mathematical-statistical learning process.




