Data Dimensionality Reduction
Data dimensionality reduction, or dimensionality reduction, is a data mapping technique. It's a key preprocessing operation in unsupervised machine learning.
Purpose? In machine learning, it's crucial for eliminating redundant (correlated) information from the dataset, which is less or not significant for solving a given problem. Training an algorithm is undoubtedly simpler and less resource-intensive with a smaller data space. Thus, it's a solution to the curse of dimensionality.
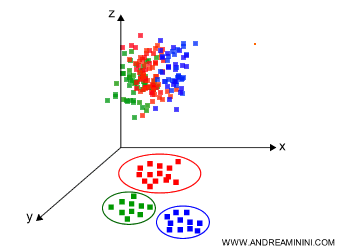
Data reduction is also used for representing data in a lower, more interpretable dimension. For instance, displaying a 3D diagram in 2D.
What is the Curse of Dimensionality?
The curse of dimensionality refers to the issue of pattern dispersion in a large volume of data.
In machine learning, handling vast amounts of data (big data) is common.
Due to high dimensionality, patterns get lost in the dataset amidst a sea of noise and insignificant data.
In such scenarios, finding a pattern becomes complex. The algorithm requires more time (temporal complexity) and memory (spatial complexity).
Dimensionality reduction reduces the volume of data to be searched without losing relevant information.
Note. Ideally, dimension reduction doesn't eliminate important information. However, a data scientist might choose to sacrifice some less relevant information for the sake of more significant ones.
How does a Dimensionality Reduction Algorithm Work?
Reducing data dimensionality doesn't just mean eliminating some dimensions (noise), but primarily involves combining redundant and correlated information.
The objectives of the algorithm are:
- Removing data noise
- Combining correlated information
A dataset initially in dimension Rn is reduced to a lower-dimensional space Rk where k<n.
The data is compressed into a more compact dimensional subspace.
To achieve this, various techniques can be employed.
Data Dimensionality Reduction Techniques
The main techniques for data dimensionality reduction include:
- Principal Component Analysis (PCA)
This technique involves unsupervised linear data mapping. It's also known as the KL (Karhunen Loeve) technique. PCA aims to identify dimensions that best represent patterns. - Linear Discriminant Analysis (LDA)
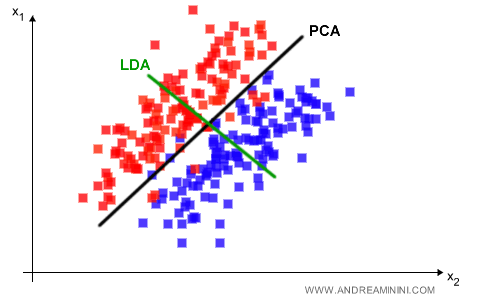
LDA is a supervised linear data mapping technique. Its goal is to identify dimensions that best discriminate patterns.PCA vs LDA Difference. In this example, I reduce the dimension from R2 to R1 using both LDA and PCA techniques. Though both work on linear mapping, they identify completely different hyperplanes (segments), thus offering alternative and complementary solutions with pros and cons. PCA preserves information, whereas LDA distinguishes between two classes better.
- t-distributed Stochastic Neighbor Embedding (t-SNE)
A non-linear, unsupervised technique used for visualizing multi-dimensional data in two or three dimensions. - Independent Component Analysis (ICA)
This technique involves linear transformation on an independent basis. - Kernel PCA
A non-linear, unsupervised mapping technique. - Local Linear Embedding (LLE)
A non-linear transformation based on local rather than global mapping. It considers only the relationships among the closest pattern groups.
Pros and Cons of Data Reduction
Data dimensionality reduction has its advantages and disadvantages.
- Advantages. It compresses the volume of data , reducing the computational complexity of the learning algorithm.
- Disadvantages. It can degrade the information and predictive performance of the learning algorithm.




