Machine Learning
Machine learning (ML) is an automatic learning system, capable of learning from examples, reasoning, and experience. It's one of the fields of study in artificial intelligence.
A machine learns through experience if its performance in executing a task improves over time after repeatedly performing it (definition by Tom Michael Mitchell).
Self-learning refers to a computer system's ability to assimilate new information without human intervention and enhance its decision-making abilities.
What Machine Learning Is Used For
Machine learning enables a machine to handle situations and problems not anticipated by its initial programming, making unprogrammed decisions and actions.
Note. In some problems, it's impossible to foresee all possible scenarios. Programmers cannot know all situations, nor predict changes in the world or know the solution to a problem. When the machine encounters an unexpected situation, it either stalls or ignores it. This is why it's preferable to give the machine some decision-making autonomy and the ability to learn.

Over time, the machine acquires new knowledge and improves its decision-making capabilities.
The software modifies itself through experience and is capable of learning from its mistakes.
How Machine Learning Works
In machine learning, algorithms don't follow pre-programmed behaviors but instead learn from data.
Computers acquire new knowledge in several ways:
- By observing the external environment
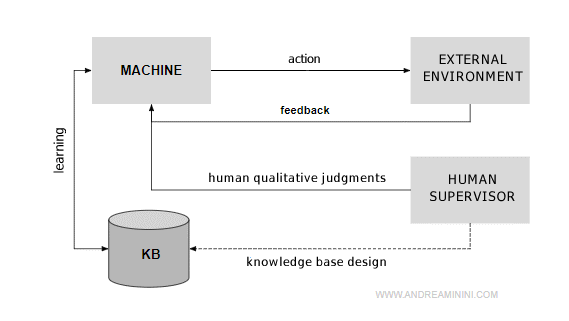
The agent observes the external world and learns from the feedback of its actions and from its mistakes. - From a knowledge base
Experience and knowledge of the operational environment are stored in a database known as the knowledge base (KB).
These two learning methods are complementary.
One does not exclude the other.
Note. There are various levels of machine learning. Some even involve human supervision. For instance, initially, the knowledge base is never empty but contains some initial information manually input by the designer ( pre-existing or prior knowledge ). Later, during the learning process, the cognitive base (KB) is modified by the agent through feedback with the environment, based on its direct experience gained over time. A human supervisor might also intervene during the ML process with qualitative judgments to aid the machine's automatic learning.
Machine Learning Techniques
The main machine learning techniques include:
- Supervised Learning
The designer provides a set of examples to the machine. Each example consists of a series of input values and is accompanied by a label indicating the desired outcome or a value judgment. The machine processes the data and learns from the examples to identify a predictive function or a general rule.
Pros and Cons. This type of machine learning is well-suited to fully observable environments with the presence of a human instructor. However, it is less effective in analyzing feedback in partially observable (PO) environments, as the agent struggles to identify cause-and-effect relationships under certain conditions. The agent is like a child learning from its environment and parents.
- Unsupervised Learning
In unsupervised learning, the agent doesn't have input-output examples to test against. There's no instructor to determine whether an action is correct or not, nor a reference measure for environmental feedback. Nonetheless, the machine can learn the existence of a link between certain input and output factors. In practice, the machine learns from its own mistakes and experience.
Pros and Cons. An agent learning in an unsupervised manner is incapable of decision-making, as it can't differentiate between right and wrong, nor does it know the correct action to take or the objectives of its actions. There is no supervisor to explain these, nor are there initial examples to analyze. Furthermore, it doesn't even know the inputs because it must find them itself. However, it can still construct a realistic and representative function of an environment's workings. The agent is like a child raised in the jungle.
- Reinforcement Learning
Reinforcement learning is based on the mechanism of rewards and punishments. The agent lacks input and output examples and doesn't have supervision to explain correct behavior. However, it has a reinforcement function associated with a goal to be achieved, allowing it to evaluate the feedback of its actions. Through experience, the agent constructs a behavioral function designed to maximize reinforcement (reward). In essence, the machine knows the goal but not how to achieve it.
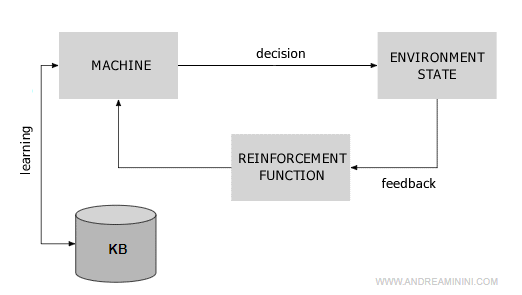
Pros and Cons. This approach combines the advantages of supervised and unsupervised learning. The agent doesn't follow the input-output patterns of the designer and doesn't need a human supervisor, allowing for fewer constraints in constructing a function representative of the environment. Additionally, thanks to reinforcement, it can distinguish desirable behaviors from negative ones and pursue a goal (maximizing the reward). Reinforcement also serves as a guiding function. The agent is like a young adult seeking their first job.

Here's the translated text, crafted to sound natural and fluent in English, using typical English expressions and sentence structures:
The Phases of the Machine Learning Process
The phases of machine learning are as follows:
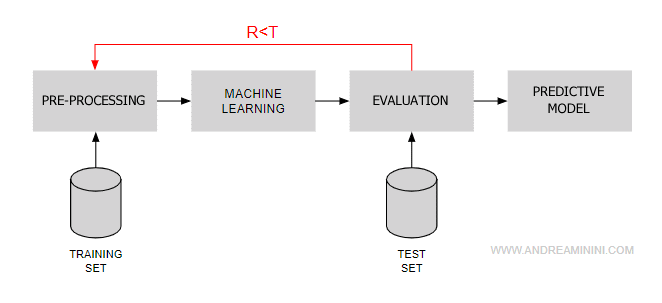
- Pre-Processing. This is the phase where I analyze the data in the learning dataset to optimize the algorithm's performance.
- Learning. This phase involves the algorithm automatically learning from the data in the learning dataset ( training set) to develop a predictive model.
- Evaluation. Here, I assess whether the predictive model created by the algorithm is accurate or not. To evaluate the predictive quality, I set a reference parameter of T percent for correct responses. I test the predictive model with a different dataset ( test set), separate from the learning dataset, and analyze the results.
- R≥T If the percentage of correct responses R exceeds the threshold T, the predictive model is approved. The machine's responses are sufficiently accurate. The margin of error in the responses is acceptable.
- R<T If the percentage of correct responses R does not exceed the threshold T, the process restarts from the pre-processing phase because the predictive quality is not effective enough.
- Prediction. This is the final application phase, where the predictive model is used with real data to solve practical problems, either by the machine itself or by end-users.
Pre-Processing
The pre-processing phase is carried out before starting an automatic learning process.
What is its purpose?
In the pre-processing phase, data in the dataset are analyzed to identify redundant information and noise.
- Noise (irrelevant data) is removed from the dataset.
- Correlated data (redu ndant) are combined.
This allows for a reduction in the dataset's dimensionality and a significant improvement in the computational complexity of the learning algorithm.
Knowledge Representation
The information acquired by the machine can be represented in various ways.
The main ones are:
- propositional logic
- first-order logic
- Bayesian networks
- neural networks
- decision trees
Knowledge representation is one of the most important technical aspects in the study of machine learning, as it significantly affects the spatial and temporal complexity of the algorithm.




