Training Set
The training set is a collection of practical examples used to build a knowledge base or a decision-making algorithm in machine learning.
How does it work? The machine analyzes the data to identify relationships between a series of input variables (e.g., properties, environmental characteristics, etc.) and a specific output variable (the target decision variable).
The training set comprises various scenarios that capture certain environmental characteristics.
Who creates the training set?
It can be generated by the machine itself by observing its surroundings.
Alternatively, an external supervisor can provide a list of examples to initiate the inductive learning process here.
What is its purpose? It is used in supervised machine learning techniques to enable the machine to learn from experience and discover cause-and-effect relationships between stochastic variables. It is also used to train expert systems.
An Example of a Training Set
This table represents ten records (rows).
Each row captures a specific situation. It's a data vector { x1, x2, ... , x10 }.
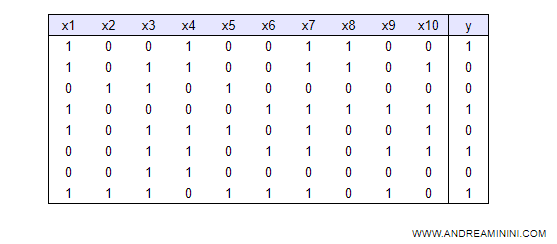
For each record, the real state of ten input variables (X) and a target variable (Y) are recorded.
Based on these observations, the machine tries to identify logical connections to construct a decision tree.
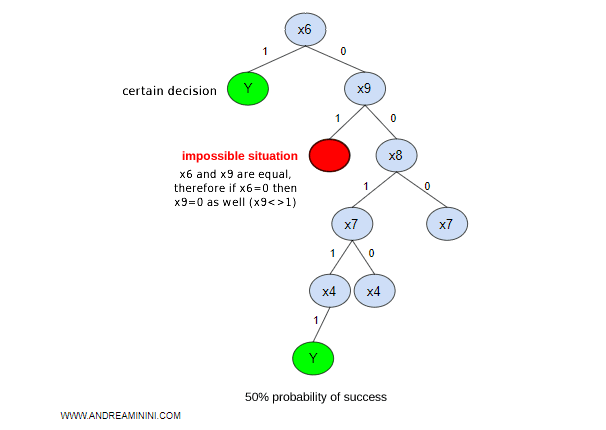
Note. In this example, I used boolean variables with true or false values for simplicity's sake, as they are the easiest to demonstrate. The same method can be applied to discrete or continuous variables, with increasing computational complexity.
How Many Examples Does the Training Set Have?
It's preferable to include many examples in the training set, as this increases the effectiveness of the training process.
Why?
A large number of examples, N, decreases the likelihood that an anomalous example will have an undue influence on the learning.
Note. If the training set is very large, it's unlikely that an anomalous hypothesis will be consistent with all the examples and is thus discarded by the learning algorithm.
According to computational learning theory, a hypothesis consistent with the examples is "probably approximately correct" (PAC) if the training set is sufficiently large.
The Difference Between Training and Test Sets
The training set should not be confused with the test set.
- The training set constructs a decision tree based on observed examples.
- The test set evaluates the effectiveness of the newly constructed decision tree, presenting the machine with situations (input vector X) to check the validity of its responses/decisions.
Thus, the training set builds the decision tree while the test set measures its effectiveness.
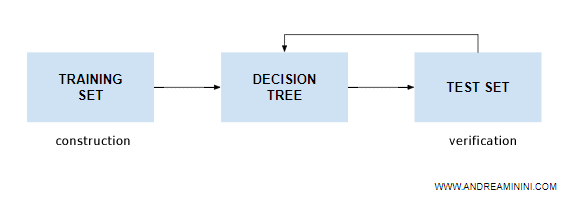
Note. If the decision tree is ineffective, i.e., provides unsatisfactory answers according to the test set, the learning process must be repeated from the beginning by expanding the training set with more examples. The machine learning process only ends when the tree correctly answers the questions contained in the test set.
According to the stationarity hypothesis, the training and test sets must be randomly drawn from the same example population with the same probability distribution.
This ensures that a hypothesis correct on the training set is very likely also correct on the test set.
Weighted Training Set
In a weighted training set, examples have different weights. Examples with a higher weight are more important.
An additional field indicating the weight (importance) of each example is added to the list of examples.
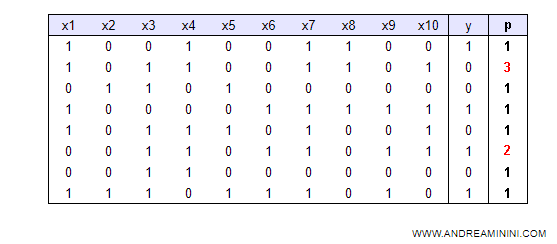
The weight becomes significant in constructing the decision tree.
In the previous table, the second example has a value of three (p=3) while the sixth example is twice as important (p=2) compared to the others (p=1).
Note. If it is not possible to add a field to the table, I can replicate an example N times and select examples to test using a random function that chooses randomly. In this way, more frequently repeated (and thus more important) examples have a higher probability of being selected during the decision tree construction. For example, the randomized form of the previous table is as follows:
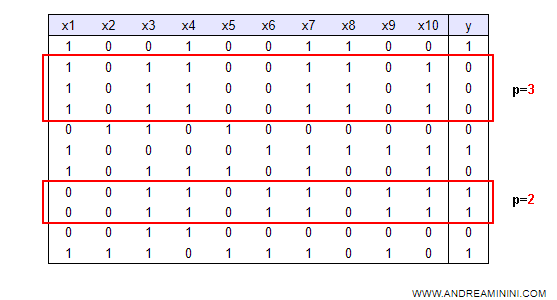
In this case, the second example is repeated three times (p=3) while the sixth example is repeated twice (p=2). All other examples appear once. The second example has a probability of 3/11 (about 27%) of being selected, the sixth example 2/11 (about 18%) and all others 1/11 (about 9%).
The weighted training set is used in boosting, a technique of ensemble learning.




