Supervised Learning
Supervised learning is a type of machine learning algorithm.
Why is it called supervised? The term supervision refers to the inclusion of solutions (labels) in the training dataset. An individual (supervisor) provides practical examples to the machine. Each example contains input variables (x) and the correct output (y). The machine learns from these examples to develop a predictive model.
Supervised machine learning is probably the most commonly used learning method in practical applications.
A Practical Example
I take a sample of emails and label each one as either "spam" or "non-spam".
The machine processes my examples to estimate a general recognition rule, known as a model.
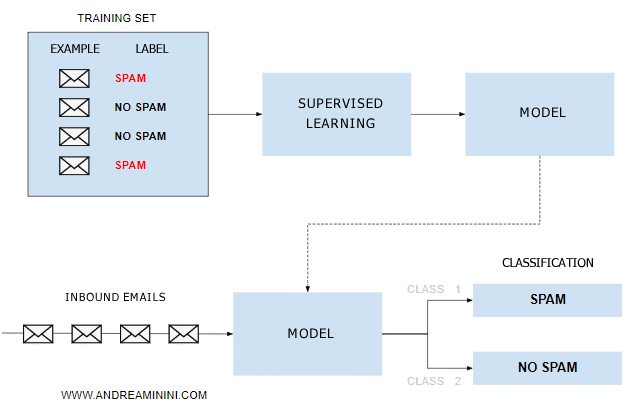
Once the model is determined, the machine uses it to classify all incoming emails as spam or non-spam.
This way, I have created a simple, intelligent anti-spam filter.
This algorithm is known as a classification algorithm.
How Supervised Learning Works
In supervised learning, the machine must estimate an unknown function f(x) that links input variables x to an output variable y.
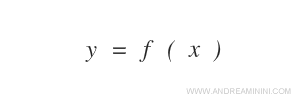
The machine doesn't know the function f(x).
Its goal is to estimate a hypothesis function h(x) that approximates f(x).
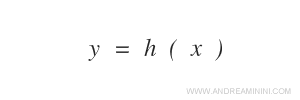
To do this, it analyzes a dataset called a training set provided by the supervisor.
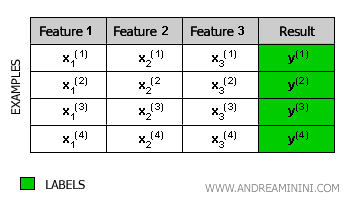
A training set is a collection of training pairs (x, y).
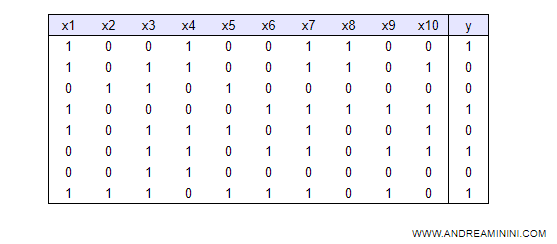
Note. Each row in the table is an example. Where Xn can be an input variable or a vector of multiple input variables, while y is the final result. Some ML algorithms can work with non-numeric data. However, supervised machine learning algorithms generally work only with numeric data. Therefore, if the dataset contains non-numeric data (e.g., strings), they must first be converted into numeric data.
Thus, the input for a supervised machine learning algorithm is a matrix with labeled examples.
From these data, the machine develops the hypothesis function h(x).
How can we tell if the hypothesis function is correct?
The machine must evaluate the accuracy of the hypothesis function h(x) to see whether it approximates the function f(x). However, it does not know the function f(x).
To understand this, it uses another dataset, called a test set, also provided by the supervisor.
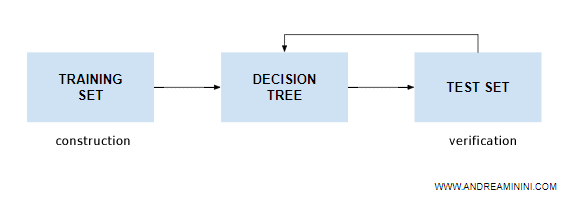
Note. Both the training set and the test set are provided by a human supervisor. However, the two sets consist of different examples. Therefore, it's advisable that they are prepared by different supervisors and not always the same ones.
The machine then responds to the Nt examples in the test set.
It then compares each of its responses R with the correct response indicated by experts (Y) in the test set.
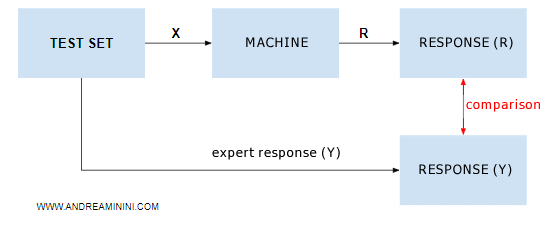
Matching responses (R=Y) increase the number of correct machine responses Rc.
If the machine's percentage of correct responses Rc/Nt is satisfactory, the hypothesis function h(x) passes the test and is accepted.
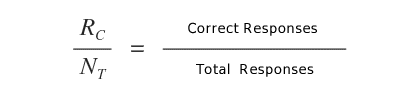
Otherwise, supervised learning restarts with the analysis of another training set.
And the cycle begins anew.
What is the output of supervised learning?
The output results of a supervised ML algorithm can be:
- real numbers
- labels
- vectors
- sequences
Types of Supervised Learning
The main categories of supervised learning are:
- Classification. The machine is trained in classification by the supervisor who adds labels to the data, judging the result. Each label is a discrete class that identifies the expected outcome (e.g., spam or non-spam) or a value judgment.
- Linear Regression. In linear regression, the result (output) is a continuous value. The machine's task is to find a relationship between input values (descriptive values) and output.




