Supervised Classification
In machine learning, classification is a type of supervised learning.
How Classification Works
The algorithm is trained by the supervisor to recognize categories through a series of practical examples (training dataset).
In each example, the machine is provided with:
- Descriptive variables of the environment (x)
- A label indicating the desired outcome (y), i.e., the class to which the example belongs.
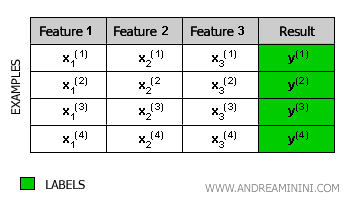
The system processes these examples to find a general classification rule, known as the model.
Once the model is built, the machine uses it to classify new instances, based on observations made on the training set.
Important. It's not the supervisor who writes the model's rules. It's the machine that discovers the rules and creates the predictive model based on the examples provided by the supervisor.
A Practical Example
To build an anti-spam filter, I train the machine to recognize spam emails.
I create a training set consisting of N examples (emails).
For each example in the set, I specify two features of the email:
- Email weight in KB (x1)
- Length of the title (x2)
Note. In this case, I deliberately created a very simple training dataset to explain the workings of automatic classification. In reality, there are many more features (x) to consider. At this point, it's especially important to emphasize that in supervised learning, it's the supervisor who selects the features for analysis, not the machine.
Then, I assign a label (y) to each example to classify it:
- spam
- not spam
Note. This example is a simple binary classification with two values (spam, not spam). In more complex cases, I might use a multiclass classification with multiple values (e.g., character and number recognition in an OCR system). The process remains the same.
With only two features (x1,x2) and one label (y), I can represent the data set on a Cartesian plane.
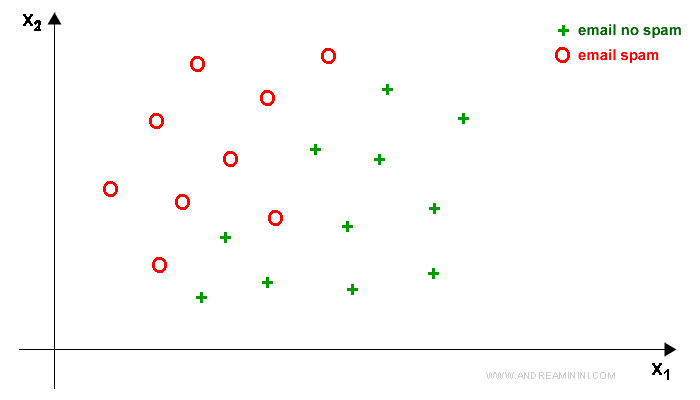
Observing the graphical representation of the data, it's immediately clear that there's a rule distinguishing spam from not spam emails.
However, the rule isn't linear and isn't easy to find.
How can I find this rule?
I could write it myself, but it would take a lot of time and I could make mistakes during programming.
So, I turn to machine learning, leaving this task to the machine.
The machine analyzes the examples in the training dataset and automatically calculates a predictive model using machine learning algorithms.
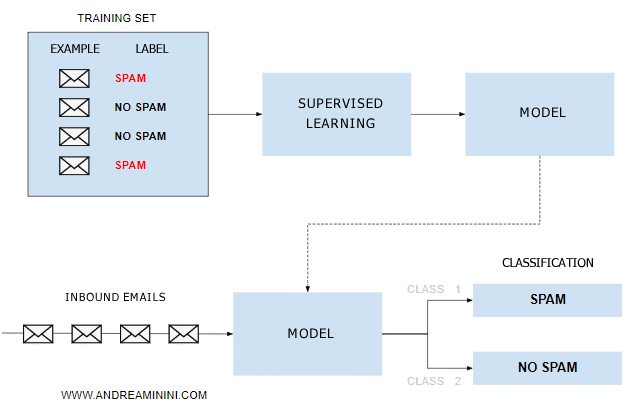
Once calculated, I can use the predictive model to analyze incoming emails.
Each incoming email is classified into spam and not spam categories.
Spam emails are recognized, separated from the others, and automatically discarded.
Note. To create this simple anti-spam filter, I didn't have to write the filtering rules. The machine learning algorithm found and wrote them by analyzing the examples I provided.
For Further Reading
For a more in-depth look, I recommend reading my notes on the Iris Model.
It's a practical example of supervised classification, developed with TensorFlow and Python. The working mechanism is the same.




