The Evolution of Deep Learning
The term deep learning (DL) emerged in the early years of the third millennium. However, the study of deep learning traces back much further. Its history is divided into three phases: cybernetics, connectionism, and modern deep learning.
The Cybernetics Era (1950s-1960s)
Deep learning research began in the 1940s with cybernetics.
The earliest DL algorithms were incorporated into neurobiological learning models inspired by living beings' brains (e.g., artificial neural networks).
Note. These were primarily simple linear mathematical models, developed to understand brain functions, not as predictive models.
Key contributions during these early years include McCulloch and Pitts (1943), Hebb (1949), and Rosenblatt (1958) on the artificial neuron.
Notably, Rosenblatt's Perceptron algorithm and the Adaline algorithm by Widroff-Hoff.
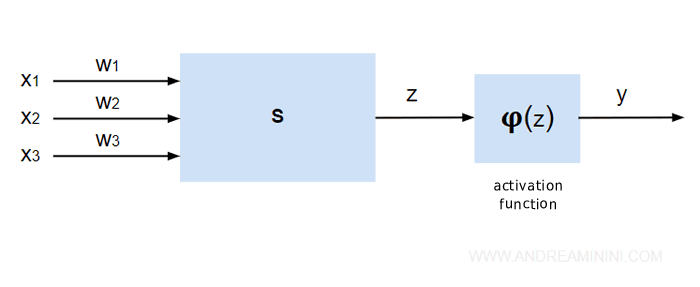
Note. The Perceptron was the first algorithm to utilize the concept of an artificial neuron. This was later adopted by Adaline, which used a stochastic gradient descent algorithm to adjust weights with a continuous function. These linear models became a benchmark for all deep learning models.
However, research stalled in 1969 when linear models, like the Perceptron, faced harsh criticism from Marvin Minsky and Seymour Papert.
In the following years, deep learning entered a period of neglect.
The Connectionism Phase (1980s-1990s)
Interest in DL resurfaced in the 1980s and 1990s with connectionism, a field within cognitive science.
What is cognitive science? Cognitive science is a multidisciplinary approach that seeks to understand how the human brain functions through computational models and symbolic reasoning.
Connectionists believed that intelligent behavior arises from a large number of simple computational units interconnected in a network.
Another significant contribution from connectionists was the backpropagation in deep neural networks.
Note. In this context, the studies on multi-layered back-propagation neural networks by Rumelhart (1986) deserve mention.
In the 1990s, the first LSTM (Long Short Term Memory) networks were developed by Hochreiter, Bengio, and Schmidhuber.
Unfortunately, the computational power of computers at the time was insufficient to fully explore these models' potential.
The hardware limitations of the era led to another phase of disinterest and disinvestment in neural networks.
Note. During these years, other research areas like kernel machines and Bayesian statistical models garnered attention, as they seemed more promising for brain simulation at the time.
Deep Learning (2006-Present)
Interest in deep learning revived in the 2000s for several reasons:
- More Powerful Hardware. Information systems achieved higher performance at lower costs. Neural networks progressively became larger, growing approximately every 2.4 years, and faster, thanks to technological innovations in computing (e.g., GPUs, multiprocessors).
- Big Data. An abundance of data became available in datasets, allowing for their processing using the same DL algorithms from the 80s, previously only applied to simpler problems.
- More Advanced DL Algorithms. Over the years, deep learning algorithms also improved, adopting a more engineering-focused approach.
Note. The size of the neural network affects its accuracy level. All else being equal, a network with more neurons is more intelligent. Due to their increased size, today's neural networks can solve problems that were unthinkable for computers 20 or 30 years ago.
Note. Big data particularly benefitted unsupervised learning algorithms, while supervised learning algorithms improved in efficiency.
Particularly, interest reignited in 2006 with Geoffrey Hinton's deep belief network model.
Hinton demonstrated how an artificial neural network could achieve complex goals efficiently.
Note. Other notable researchers include Bengio (2007), Ranzato (2007), Nair, Glorot, and Jarrett.
The term deep learning, meaning in-depth (or deep) learning, was finally coined during these years.
The adjective "deep" refers to the increased depth of the neural network.
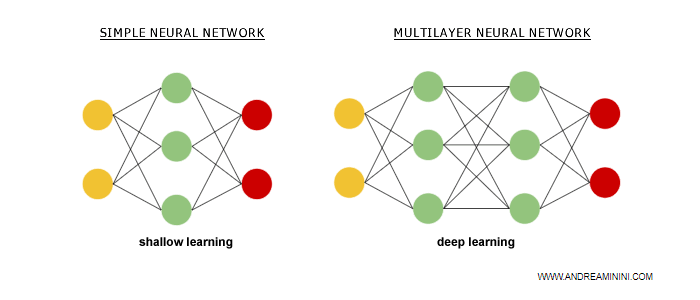
These new learning models are developed on multi-layered neural networks with several hidden layers.
They are based on a neuron model called simplified linear unit (rectified linear unit), a simplification of Fukushima's Cognitron model from 1975.
However, they are no longer inspired by neurobiological models and neuroscience, as were their predecessors.
Why the waning interest in neuroscience? Interest in neuroscience diminished due to the scant information about how the human brain functions. It's challenging to build a computational model based on something that is little understood. Today, the study of biological brain functioning continues under computational neuroscience, a field distinct and separate from deep learning.
Current deep learning models are much closer to computer engineering than neuroscience.
They are developed using mathematical foundations such as linear algebra, probability theory, and information theory.
Therefore, it is incorrect today to consider deep learning as an attempt to simulate the human brain.
The story of deep learning is still unfolding, and its future evolution is hard to predict.
I will update this page as significant advancements occur.




